By Steve Endow
Uncle. I give up. I have lost the fight.
![]()
Email has won. I am defeated.
What was once a great tool for communication has become an overbearing hassle that has destroyed my productivity.
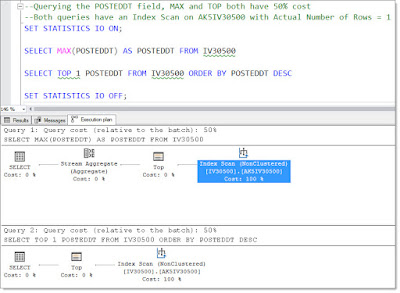
I receive around 50 to 75 emails every weekday. On a very bad day, I'll hit 100 emails. I've determined that 100 inbound emails a day is completely unmanageable for me. With my current processes (or lack thereof), I cannot possibly be productive with that many emails coming at me. The number of responses and tasks from 100 emails prevents me from doing any other work.
If all I did was "manage" my email all day, and do nothing else, I could probably wrangle my Inbox, but I wouldn't get any "real work" done. When I focus on doing real work and ignore my email for a day, my Inbox explodes.
It isn't just the emails themselves. It's also that many of the emails have some type of commitment attached to them.
"Hey Steve, please review this thread of 30 cryptic replies below and let me know what you think."
"Here's the 15 page document I created, please proofread it."
"When can you schedule a call?"
"We are getting an error. What is causing this?"
"Here are links to a forum post and KB article. Does this explain the error I'm getting?"
"How many hours will it take you to do X?"
"I sent you an email earlier? Did you get my email? Can you reply to my email?"
People seem to expecting a relatively prompt reply to their emails--because they think their request is most important, naturally, and because I don't have any other work to do, right?
This week, a link to this article appeared in my Twitter feed:
One-Touch to Inbox Zero
By Tiago Forte of Forte Labs
![]()
I have heard of Inbox Zero previously, but I had dismissed it as a bit of a gimmick without fully understanding it.
This time, I actually read the article by Tiago Forte and his explanation finally clicked for me. His examples and analogies made sense, and his emphasis on email as the first step of a more comprehensive communication and productivity workflow helped me build a new interpretation of Inbox Zero.
I previously saw email as the problem, but after reading the article, I suspect that my overflowing Inbox is really just a symptom of other underlying problems.
For example:
1. When it comes to email, I'm not organized--I don't have a system for dealing with the flood of emails. They just pile up.
2. I'm using email as an organizational system. As Tiago points out with his mailbox analogy, this doesn't make any sense, and is not effective.
3. I very likely have a capacity problem. If I fully implement his Inbox Zero workflow, I suspect that my Task list is going to grow out of control. But that's probably a good thing. At least then I will better understand my capacity problem, instead of blaming it on the emails flooding my Inbox.
The Inbox Zero article helps address email organization by proposing a simple, but strict workflow for all emails that are in your Inbox.
The Inbox is not a place to work. It is simply the place where your email arrives and is sorted. Just as you don't stand in front of your mailbox at home to tear open and pay your bills or read your magazines in your yard, you don't work on your email from your Inbox. And as he explains, when you visit your mailbox, you don't let your mail pile up in the mailbox--you remove the mail and deal with it elsewhere.
Got it.
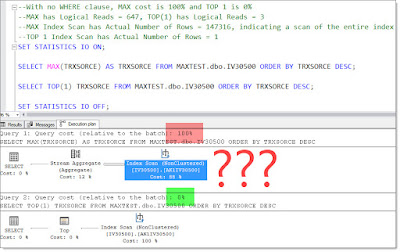
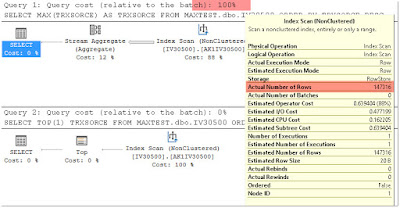
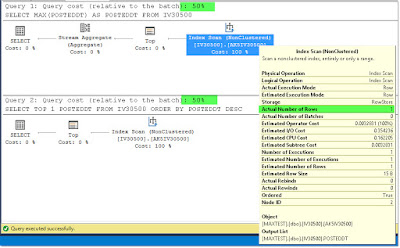
Based on the recommendations in the article, I cleared out as many emails as I could from my Inbox, and was left with 149 emails that I probably needed to deal with. I temporarily moved those to a "To Do" folder for the time being, and I quickly felt a sense of accomplishment with an empty Inbox.
![]()
I then started working on setting up the "four downstream systems" to support his Inbox Zero workflow.
1. Calendar
2. Task
3. Reference
4. Read Later
Here is his nice graphic of the workflow:
![]()
The challenge was that he uses GMail and OS X, so his recommended tools aren't really applicable to Outlook (using MS Exchange) on Windows, and iPhone with default iOS apps that I use.
And while I have previously tried Evernote, I find that I prefer the more structured nature of OneNote.
So I spent the day figuring out how to implement his workflow in my environment.
Here's what I came up with.
![]()
1. Outlook 2016 Mail (MS Exchange) on Windows with a single mailbox, which syncs to iOS Mail on my iPhone / iPad
2. Outlook Calendar on Windows, which syncs to iOS Calendar on my iPhone / iPad
3. Outlook Tasks on Windows, which syncs to iOS Reminders on my iPhone / iPad
4. OneNote on Windows, which syncs to OneNote app on my iPhone / iPad
5. Pocket Chrome Extension on Windows and Pocket app on my iPhone / iPad. I prefer the article formatting provided by Pocket, so I use it instead of Instapaper. And the Pocket email service appears to be much better at picking out a URL from an email message, whereas Instapaper seems to require a blank email with only a single URL.
The one downside to Pocket is that the free version includes ads in your reading list, which you have to ignore or hide, unless you want to pay for a Premium subscription. I'll see how much I use it and whether it's worth the subscription, or whether I want to use Instapaper instead.
To streamline the 6 numbered steps in his workflow, I setup the following steps and shortcuts.
Outlook 2016 apparently doesn't support custom keyboard shortcuts for specific commands, but it allows you to setup "Quick Steps", which can be assigned shortcuts of CTRL+SHIFT+ (0-9).
![]()
I setup four Quick Steps to provide keyboard shortcuts for flows 1, 3, 4, and 6. Note that these Quick Steps only work when you are in Mail view in Outlook, as they operate on the message you have selected.
Here are all 6 of the flows:
1. Archive: CTRL+SHIFT+9. This moves the selected or open email to my single archive folder. I do not categorize messages into different folders, as the Search feature is finally good enough that I Search instead of looking through different folders. I have been using this Quick Step for years, so it was already done. I chose the number 9 because I typically press CTRL+SHIFT with my left hand, making 9 easy to press with my right hand.
2. Reply: Outlook on Windows offers CTRL+R for Reply, and CTRL+SHIFT+R for Reply to All.
3. Add to Calendar: CTRL+SHIFT+8 creates a new appointment and includes the text of the selected email in the body / note section of the appointment. I chose to use the message text, as that will be easier for me and any calendar invite recipients to read.
![]()
4. Add Task: CTRL+SHIFT+7 creates a new Task and attaches the selected email to the Task. For this Quick Step, I chose to attach the email (instead of copy text of the message) because I suspect I will need to open the email so that I have the option to reply, view message attachments, etc. when I work on the task.
5. Add to Reference: Since I use OneNote, I will click on the Add To OneNote button in the main Outlook ribbon. I have been using OneNote for several years and have been using this button, so this flow was already in place.
![]()
6. Read Later: CTRL+SHIFT+6 forwards the selected email to add@getpocket.com, which will automatically add the first URL in the email to your reading list. Any additional URLs in the email will be ignored, so I may have to edit the emails before sending them to ensure that the desired URL is first in the email.
In addition to setting up these flows, I modified my Outlook Inbox view to sort messages by date ascending, so they would be listed from oldest to newest, per Tiago's recommendation.
As he instructs, I also enabled threading, "Show as Conversations" in Outlook, which is something I have resisted for years. I didn't like threading because when my Inbox was filled with hundreds of messages, the threading often made it difficult to review messages. But if my Inbox stays lean, threading should help me better deal with the occasional flurries of Reply All conversations and start with the last message in the thread.
![]()
So, in theory, these 6 steps will allow you to very quickly sort through the email in your Inbox and keep it empty.
Okay, I get that. But there are two concerns I have at the beginning of my Inbox Zero journey, including one which I referenced earlier.
1. Replying to email can be time consuming. So I suspect I am going to have to come up with criteria for when to reply directly to an email from my Inbox. Single word replies only? Yes, No, Okay, Thanks? What about if someone asks me for 3 dates/times when I'm available for a call next week? That reply could take a minute to compose. What if they ask me a question that will take 2 minutes for me to answer? I'll need some way to assess how long it will take to reply. If it will take more than X seconds or require me to do research or do additional work to reply, I'll move it to a task.
2. What happens when my Inbox is empty, but my Task List keeps growing with the list of emails that I've converted to tasks? Just as I'm unable to respond to all of my current emails, I have the strong suspicion that I'm going to be unable to get to all of the new Tasks that those same emails are going to create.
Aside from these two items that I'm going to have to figure out, I think it's a good start.
Now that I've got things setup, I need to go through the 149 messages in my temporary To Do folder and use them to practice this new workflow.
Have you implemented an Inbox Zero workflow? If so, how is it different than Tiago's process that I'm testing? Are there any other tips, tools, or techniques that you have found helpful for dealing with email and being more productive?
![]()
![]()
Uncle. I give up. I have lost the fight.

Email has won. I am defeated.
What was once a great tool for communication has become an overbearing hassle that has destroyed my productivity.
I receive around 50 to 75 emails every weekday. On a very bad day, I'll hit 100 emails. I've determined that 100 inbound emails a day is completely unmanageable for me. With my current processes (or lack thereof), I cannot possibly be productive with that many emails coming at me. The number of responses and tasks from 100 emails prevents me from doing any other work.
If all I did was "manage" my email all day, and do nothing else, I could probably wrangle my Inbox, but I wouldn't get any "real work" done. When I focus on doing real work and ignore my email for a day, my Inbox explodes.
It isn't just the emails themselves. It's also that many of the emails have some type of commitment attached to them.
"Hey Steve, please review this thread of 30 cryptic replies below and let me know what you think."
"Here's the 15 page document I created, please proofread it."
"When can you schedule a call?"
"We are getting an error. What is causing this?"
"Here are links to a forum post and KB article. Does this explain the error I'm getting?"
"How many hours will it take you to do X?"
"I sent you an email earlier? Did you get my email? Can you reply to my email?"
People seem to expecting a relatively prompt reply to their emails--because they think their request is most important, naturally, and because I don't have any other work to do, right?
This week, a link to this article appeared in my Twitter feed:
One-Touch to Inbox Zero
By Tiago Forte of Forte Labs

I have heard of Inbox Zero previously, but I had dismissed it as a bit of a gimmick without fully understanding it.
This time, I actually read the article by Tiago Forte and his explanation finally clicked for me. His examples and analogies made sense, and his emphasis on email as the first step of a more comprehensive communication and productivity workflow helped me build a new interpretation of Inbox Zero.
I previously saw email as the problem, but after reading the article, I suspect that my overflowing Inbox is really just a symptom of other underlying problems.
For example:
1. When it comes to email, I'm not organized--I don't have a system for dealing with the flood of emails. They just pile up.
2. I'm using email as an organizational system. As Tiago points out with his mailbox analogy, this doesn't make any sense, and is not effective.
3. I very likely have a capacity problem. If I fully implement his Inbox Zero workflow, I suspect that my Task list is going to grow out of control. But that's probably a good thing. At least then I will better understand my capacity problem, instead of blaming it on the emails flooding my Inbox.
The Inbox Zero article helps address email organization by proposing a simple, but strict workflow for all emails that are in your Inbox.
The Inbox is not a place to work. It is simply the place where your email arrives and is sorted. Just as you don't stand in front of your mailbox at home to tear open and pay your bills or read your magazines in your yard, you don't work on your email from your Inbox. And as he explains, when you visit your mailbox, you don't let your mail pile up in the mailbox--you remove the mail and deal with it elsewhere.
Got it.
Based on the recommendations in the article, I cleared out as many emails as I could from my Inbox, and was left with 149 emails that I probably needed to deal with. I temporarily moved those to a "To Do" folder for the time being, and I quickly felt a sense of accomplishment with an empty Inbox.

I then started working on setting up the "four downstream systems" to support his Inbox Zero workflow.
1. Calendar
2. Task
3. Reference
4. Read Later
Here is his nice graphic of the workflow:

The challenge was that he uses GMail and OS X, so his recommended tools aren't really applicable to Outlook (using MS Exchange) on Windows, and iPhone with default iOS apps that I use.
And while I have previously tried Evernote, I find that I prefer the more structured nature of OneNote.
So I spent the day figuring out how to implement his workflow in my environment.
Here's what I came up with.

1. Outlook 2016 Mail (MS Exchange) on Windows with a single mailbox, which syncs to iOS Mail on my iPhone / iPad
2. Outlook Calendar on Windows, which syncs to iOS Calendar on my iPhone / iPad
3. Outlook Tasks on Windows, which syncs to iOS Reminders on my iPhone / iPad
4. OneNote on Windows, which syncs to OneNote app on my iPhone / iPad
5. Pocket Chrome Extension on Windows and Pocket app on my iPhone / iPad. I prefer the article formatting provided by Pocket, so I use it instead of Instapaper. And the Pocket email service appears to be much better at picking out a URL from an email message, whereas Instapaper seems to require a blank email with only a single URL.
The one downside to Pocket is that the free version includes ads in your reading list, which you have to ignore or hide, unless you want to pay for a Premium subscription. I'll see how much I use it and whether it's worth the subscription, or whether I want to use Instapaper instead.
To streamline the 6 numbered steps in his workflow, I setup the following steps and shortcuts.
Outlook 2016 apparently doesn't support custom keyboard shortcuts for specific commands, but it allows you to setup "Quick Steps", which can be assigned shortcuts of CTRL+SHIFT+ (0-9).

I setup four Quick Steps to provide keyboard shortcuts for flows 1, 3, 4, and 6. Note that these Quick Steps only work when you are in Mail view in Outlook, as they operate on the message you have selected.
Here are all 6 of the flows:
1. Archive: CTRL+SHIFT+9. This moves the selected or open email to my single archive folder. I do not categorize messages into different folders, as the Search feature is finally good enough that I Search instead of looking through different folders. I have been using this Quick Step for years, so it was already done. I chose the number 9 because I typically press CTRL+SHIFT with my left hand, making 9 easy to press with my right hand.
2. Reply: Outlook on Windows offers CTRL+R for Reply, and CTRL+SHIFT+R for Reply to All.
3. Add to Calendar: CTRL+SHIFT+8 creates a new appointment and includes the text of the selected email in the body / note section of the appointment. I chose to use the message text, as that will be easier for me and any calendar invite recipients to read.

4. Add Task: CTRL+SHIFT+7 creates a new Task and attaches the selected email to the Task. For this Quick Step, I chose to attach the email (instead of copy text of the message) because I suspect I will need to open the email so that I have the option to reply, view message attachments, etc. when I work on the task.
5. Add to Reference: Since I use OneNote, I will click on the Add To OneNote button in the main Outlook ribbon. I have been using OneNote for several years and have been using this button, so this flow was already in place.

6. Read Later: CTRL+SHIFT+6 forwards the selected email to add@getpocket.com, which will automatically add the first URL in the email to your reading list. Any additional URLs in the email will be ignored, so I may have to edit the emails before sending them to ensure that the desired URL is first in the email.
In addition to setting up these flows, I modified my Outlook Inbox view to sort messages by date ascending, so they would be listed from oldest to newest, per Tiago's recommendation.
As he instructs, I also enabled threading, "Show as Conversations" in Outlook, which is something I have resisted for years. I didn't like threading because when my Inbox was filled with hundreds of messages, the threading often made it difficult to review messages. But if my Inbox stays lean, threading should help me better deal with the occasional flurries of Reply All conversations and start with the last message in the thread.

So, in theory, these 6 steps will allow you to very quickly sort through the email in your Inbox and keep it empty.
Okay, I get that. But there are two concerns I have at the beginning of my Inbox Zero journey, including one which I referenced earlier.
1. Replying to email can be time consuming. So I suspect I am going to have to come up with criteria for when to reply directly to an email from my Inbox. Single word replies only? Yes, No, Okay, Thanks? What about if someone asks me for 3 dates/times when I'm available for a call next week? That reply could take a minute to compose. What if they ask me a question that will take 2 minutes for me to answer? I'll need some way to assess how long it will take to reply. If it will take more than X seconds or require me to do research or do additional work to reply, I'll move it to a task.
2. What happens when my Inbox is empty, but my Task List keeps growing with the list of emails that I've converted to tasks? Just as I'm unable to respond to all of my current emails, I have the strong suspicion that I'm going to be unable to get to all of the new Tasks that those same emails are going to create.
Aside from these two items that I'm going to have to figure out, I think it's a good start.
Now that I've got things setup, I need to go through the 149 messages in my temporary To Do folder and use them to practice this new workflow.
Have you implemented an Inbox Zero workflow? If so, how is it different than Tiago's process that I'm testing? Are there any other tips, tools, or techniques that you have found helpful for dealing with email and being more productive?
Steve Endow is a Microsoft MVP in Los Angeles. He is the owner of Precipio Services, which provides Dynamics GP integrations, customizations, and automation solutions.